Un paio di settimane fa sono stato invitato da Ivan Grieco e Umberto Bertonelli a una chat su YouTube decisamente a ruota libera su una varietà di argomenti, dall’energia nucleare all’intelligenza artificiale a 2001 Odissea nello spazio. Se vi interessa, è incorporata qui sotto.
2022/06/29
Quando MacOS si rifiuta di vedere i dischi di rete
Ogni tanto MacOS si rifiuta di vedere i dischi condivisi, specialmente dopo uno scollegamento imprevisto a causa di un inciampo su un cavo o simili (tipo quello che mi è successo stamattina): il Finder mostra la condivisione, ma non riesce più ad accedere al contenuto della condivisione. Normalmente si “risolve” il problema riavviando il Mac, ma se succede nel bel mezzo di un lavoro importante riavviare è una scocciatura notevole.
Se vi dovesse capitare, aprite Terminale e digitate
sudo ifconfig en0 down
oppure
sudo ifconfig en1 down
a seconda della rete (Ethernet o Wi-Fi) sulla quale c’è il problema, digitate la vostra password utente, aspettate un paio di secondi e poi digitate
sudo ifconfig en0 up
oppure
sudo ifconfig en1 up
Bingo! Problema risolto. I servizi di rete vengono riavviati senza dover far
ripartire il Mac. Me lo segno qui, così me lo ricordo e magari può essere
utile a qualcuno.
2022/06/27
Google Analytics, stop anche dal Garante italiano: quanti siti non sono in regola?
Anche il Garante Privacy italiano, dopo quello austriaco e francese, ha dichiarato che usare Google Analytics va contro la normativa europea GDPR perché raccoglie informazioni personali sui visitatori e le manda negli Stati Uniti (o comunque le rende disponibili alle aziende e alle autorità governative statunitensi perché è un’azienda statunitense, sia pure residente in UE), e gli USA non sono considerati un paese sicuro per la protezione dei dati per via della maggiore facilità di accesso per profilazione commerciale o di sorveglianza politica.
Il Garante ha già emesso un primo provvedimento che riguarda una Srl italiana. La questione è raccontata in dettaglio su Punto Informatico, che linka anche i dettagli del provvedimento.
I siti italiani non in regola sono tantissimi: migliaia già soltanto considerando quelli della pubblica amministrazione, che non si capisce perché debbano appoggiarsi a Google quando esiste un sistema di analytics nazionale e conforme alle norme di protezione dei dati personali (webanalytics.italia.it). Ne parla Matteo Flora in questo video, spiegando la tecnica usata da Fabio Pietrosanti per documentare la situazione:
Sempre Flora affronta la questione insieme a Guido Scorza, che è uno dei componenti del Garante italiano, e insieme a due avvocati, Gianluca Gilardi e Andrea Michinelli, che propongono alcune soluzioni (come Matomo o Piwik Pro, discussi nel secondo video da Gilardi intorno a 32 minuti).
Michinelli spiega ulteriori dettagli in questo articolo su Cybersecurity360.it.
Il problema è davvero grosso per moltissime aziende e per la pubblica amministrazione, che si troveranno presto costrette a una radicale ristrutturazione dei propri siti, e anche per i privati che gestiscono un sito ospitato da Google, come per esempio questo blog.
Sottolineo che non si tratta di una questione solo italiana: sono coinvolti tutti i garanti europei. Sottolineo inoltre che, come notano gli ospiti di Matteo Flora, non è neanche questione di dove stanno i server. Possono anche essere fisicamente nell’UE, ma se sono intestati a un’azienda statunitense sono comunque disponibili ai governi USA.
E questo blog come è messo? Ne ho parlato qui a maggio scorso. Da parte mia, come utente di Blogger (che è di Google), credo di aver fatto tutto il possibile per evitare l’uso di Google Analytics:
- Ho verificato di aver disabilitato Google Analytics in questo blog e in tutti gli altri che gestisco, secondo l’invito e il comunicato del Garante Privacy italiano del 23 giugno 2022 e le sue linee guida del 10 giugno 2021. L’ho fatto andando nelle Impostazioni del blog, scegliendo la voce ID proprietà di Google Analytics, cliccandovi sopra e verificando che la voce era vuota (lo era probabilmente da parecchio tempo).
- Ho inoltre disabilitato in tutti i blog che gestisco Google Marketing Platform, andando nelle Impostazioni del blog, scegliendo la voce Abilita file ads.txt personalizzato e disattivandola.
Se ci sono altre cose che posso fare per ridurre la profilazione fatta da terzi, ditemelo.
Sarebbe una magagna molto pesante se questo non bastasse e fosse necessario abbandonare completamente la piattaforma Google per questo blog e gli altri che gestisco.
2022/06/24
Podcast RSI - Trucchi delle intelligenze artificiali; arresti Interpol rivelano tecniche dei criminali online; attacchi informatici ai dispositivi QNAP... e alle vasche idromassaggio

È disponibile subito il podcast di oggi de Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso www.rsi.ch/ildisinformatico (link diretto) e qui sotto.
I podcast del Disinformatico sono ascoltabili anche tramite feed RSS, iTunes, Google Podcasts e Spotify.
Buon ascolto, e se vi interessano i testi e i link alle fonti di questa puntata, sono qui sotto.
2022/06/23
Vasche da bagno a rischio attacco informatico
 Di tutte le cose che possono essere prese di mira da un attacco informatico, la
vasca da bagno con idromassaggio sembrerebbe essere proprio l’ultima, ma è quello
che è successo di recente. Un ricercatore californiano di sicurezza informatica,
Eaton Zveare, ha trovato il modo di accedere via Internet ai dati personali
degli utenti delle vasche “smart” commercializzate da Jacuzzi e da altre marche
molto note del settore e prenderne il controllo.
Di tutte le cose che possono essere prese di mira da un attacco informatico, la
vasca da bagno con idromassaggio sembrerebbe essere proprio l’ultima, ma è quello
che è successo di recente. Un ricercatore californiano di sicurezza informatica,
Eaton Zveare, ha trovato il modo di accedere via Internet ai dati personali
degli utenti delle vasche “smart” commercializzate da Jacuzzi e da altre marche
molto note del settore e prenderne il controllo.
Pochi giorni fa il ricercatore ha raccontato la bizzarra vicenda nel suo sito: ha ordinato per sé una di queste vasche aggiungendo l’opzione, denominata SmartTub, che aggiunge alla vasca un modulo ricetrasmettitore che usa la rete cellulare per mandare informazioni a un’app che permette di comandare a distanza la vasca, accendendo le luci, regolando i getti e la temperatura dell’acqua, e così via. Lo so, può sembrare una funzione extralusso, ma sono oltre 10.000 le persone che hanno scaricato l’app da Google Play e quindi, si presume, la usano.
Durante la configurazione dell’app, il ricercatore ha visto comparire sul suo schermo per un attimo una tabella piena di dati. L’ha catturata usando uno screen recorder per registrare quell’immagine fugace e ha scoperto che si trattava di un pannello di controllo per amministratori, strapieno di dati di utenti di vasche con idromassaggio di varie marche.

Da bravo informatico, ha approfondito l’indagine e ha scoperto che il pannello di controllo era accessibile a chiunque senza immettere credenziali e consentiva di vedere e modificare i dettagli dei proprietari delle vasche, con nomi, cognomi e indirizzi di mail, e anche di disabilitare completamente gli account.
In maniera molto responsabile, Eaton Zveare ha contattato il supporto tecnico dell’app di Jacuzzi per avvisare l’azienda del problema. Ha ricevuto risposta e ha fornito tutti i dettagli tecnici, ma poi non ha sentito più nulla per mesi, mentre la falla rimaneva aperta. Ha dovuto tentare vari altri indirizzi di contatto e infine rivolgersi alla società di sicurezza informatica Auth0, che gestisce il sistema di accesso alle vasche da bagno “smart”, prima di ottenere risposta. Un copione che chiunque lavori nella sicurezza informatica ha già vissuto tante volte.
Ma alla fine, dopo sei mesi, la falla è stata chiusa, senza neppure un cenno di riconoscimento o ringraziamento da parte della casa produttrice di vasche, alla quale il ricercatore ha risolto gratuitamente un guaio che avrebbe potuto avere conseguenze legali molto onerose. Anche questo silenzio fa parte del copione.
C’è di più. Secondo le leggi della California, dove ha sede la Jacuzzi, questa fuga di dati dei clienti dovrebbe essere annunciata ai clienti stessi e segnalata alle autorità, ma finora non risulta che ci sia stato alcun annuncio o segnalazione. Se questo è il modo in cui si gestiscono i dati degli utenti e i comandi remoti dei loro elettrodomestici, forse conviene cercare elettrodomestici che non siano così tanto “smart”.
Interpol, duemila arresti per truffe informatiche, 50 milioni di dollari recuperati

Le forze di polizia che hanno partecipato all’operazione hanno perquisito i
call center dai quali si sospetta che partissero truffe telematiche di
tutti i generi, dal romance scam (il finto corteggiamento che si
conclude con una richiesta di denaro per un’emergenza inesistente) alle frodi
bancarie online. Paradossalmente, l’Interpol segnala che sono in aumento i
criminali che si fingono funzionari dell’Interpol e si fanno dare denaro dalle
vittime che credono di essere sotto indagine.
L’annuncio dell’Interpol è interessante non solo per la vastità dell’azione di polizia, ma anche per la varietà delle tecniche di raggiro descritte.
Per esempio, a Singapore, la polizia ha salvato una persona molto giovane che era stata convinta con l’inganno a fingere di essere stata rapita, mandando ai genitori video in cui mostrava finte ferite e veniva fatta una richiesta di riscatto di un milione e mezzo di euro.
In Papua Nuova Guinea, un cittadino cinese è stato arrestato perché sospettato di aver frodato circa 24.000 vittime, per un totale di circa 34 milioni di euro, usando uno schema Ponzi di vendita piramidale.
Altri otto sospettati sono stati arrestati, sempre a Singapore, con l‘accusa
di aver creato uno schema Ponzi legato alle offerte di lavoro, nel quale le
vittime dovevano reclutare altri membri per guadagnare delle commissioni.
L’Interpol sottolinea inoltre il fenomeno in crescita dei money mule, ossia degli utenti che ricevono denaro sui propri conti, credendo di fare un lavoro onesto di intermediazione finanziaria, e scoprono solo in seguito che i soldi ricevuti provengono da reati e che quindi loro sono dei riciclatori inconsapevoli. L’Interpol cita anche il problema delle “piattaforme dei social media che stanno alimentando il traffico di esseri umani, intrappolando le persone in forme di schiavitù lavorativa o sessuale o in prigionia nei casinò o sui pescherecci.”
Naturalmente questi arresti da soli non bastano a fermare le attività criminali di questo genere, anche se sono un aiuto notevole oltre che una consolazione per le vittime. Serve anche una diffusa conoscenza di queste truffe e delle loro tecniche, in modo da saperle riconoscere. Magari voi avete già questa conoscenza, ma qualcuno nella vostra famiglia è più vulnerabile e meno informato. Parlatene e mettete in guardia:
- mai fidarsi dei contatti esclusivamente telefonici o via mail o messaggi;
- mai dare informazioni personali, anche se sembrano poco pericolose, se non si è sicurissimi dell’identità dei propri interlocutori;
- mai inviare denaro a nessuno, non importa quanto sia commovente la sua storia o quanto sia promettente la sua offerta di moltiplicare questo denaro;
- mai accettare proposte troppo belle per essere vere;
- nel dubbio, fermatevi, non fatevi mettere fretta da nessuno e chiedete aiuto a una persona fidata
-
e per finire, se un amico o un familiare vi dice che forse qualcuno sta
cercando di truffarvi, ascoltatelo: come
dice
Paul Ducklin della società di sicurezza informatica Sophos, non lasciate che
i truffatori vi separino dalle persone che amate, oltre che dai vostri
soldi.
Mettete al sicuro i vostri dati su un disco condiviso QNAP? Aggiornatelo per evitare ricatti

Una delle marche più note nel settore dei dischi condivisi o NAS (network attached storage) è QNAP, ma quest’azienda ha diffuso da poco un avviso di sicurezza importante: chi non ha aggiornato il software presente a bordo di questi NAS è a rischio di ricatto e di furto o perdita di dati.
L’azienda segnala infatti che è in corso una campagna di ransomware ai danni degli utenti dei suoi dispositivi. Criminali non identificati riescono a localizzare e a infettare via Internet i NAS QNAP non aggiornati, usando un malware denominato DeadBolt per mettere una password su tutti i dati che contengono e poi chiedono un riscatto per dare alla vittima la password di sblocco dei suoi dati.
Chi non paga il riscatto e non ha una seconda copia di questi dati rischia di perderli per sempre, e c’è il rischio aggiuntivo che eventuali foto e video di natura intima archiviati sul NAS possano essere oggetto di ulteriore ricatto o finire nelle mani sbagliate.

Credit: Bitdefender.
QNAP consiglia quindi agli utenti di aggiornare al più presto il software di gestione dei propri dischi di rete condivisi, seguendo la procedura indicata nell’avviso. Aggiunge inoltre che se si è già stati attaccati è importante fare uno screenshot della richiesta di riscatto prima di aggiornare il software, perché l’aggiornamento cancellerà la richiesta, rendendo impossibile comunicare con i criminali per un eventuale recupero dei dati.
A prescindere dal caso specifico, gli esperti di sicurezza
raccomandano
di non collegare mai nessun NAS, di nessuna marca, direttamente a Internet, ma
di farlo solo se strettamente necessario e comunque proteggendolo tramite un
apposito firewall ben configurato.
Software “senziente”: come sapere se NON lo è
Nella scorsa puntata del mio podcast ho raccontato la strana storia di LaMDA, il software che secondo un ricercatore di Google, Blake Lemoine, sarebbe diventato senziente. C’è un aggiornamento che chiarisce molto efficacemente come stanno davvero le cose e leva ogni ragionevole dubbio.
Il canale YouTube Computerphile ha intervistato sull’argomento Michael Pound, che è Assistant Professor in Computer Vision presso l’Università di Nottingham, nel Regno Unito:
La sua valutazione è lapidaria: no, LaMDA non è senziente. Michael Pound spiega bene perché, descrivendo il funzionamento di questi grandi modelli linguistici ed evidenziando due frasi dette da LaMDA che, se esaminate con freddezza e competenza, rivelano i “trucchi” usati dal software per dare una forte illusione di intelligenza. Vediamoli insieme.
La prima osservazione dell’esperto è che questi software usano un metodo molto semplice per costruire frasi che sembrano apparentemente sensate e prodotte da un intelletto: assegnano dei valori alle singole parole scritte dal loro interlocutore sulla base della loro frequenza, relazione e rilevanza negli enormi archivi di testi (scritti da esseri umani) che hanno a disposizione e generano sequenze di parole che rispettano gli stessi criteri.
Insomma, non c’è alcun meccanismo di comprensione: c’è solo una elaborazione statistica. Se le parole immesse dall’interlocutore fossero prive di senso, il software risponderebbe con parole dello stesso tipo, senza potersi rendere conto di scrivere delle assurdità. Se gli si chiede di scrivere una poesia nello stile di un certo poeta, il software è in grado di attingere alla collezione delle opere di quel poeta, analizzare le frequenze, le posizioni e le relazioni delle parole e generare una poesia che ha le stesse caratteristiche. Ma lo farà anche nel caso di un poeta inesistente, come illustra l’esempio proposto da Computerphile, e questo sembra essere un ottimo metodo per capire se c’è reale comprensione del testo o no.

La seconda osservazione dell’esperto Michael Pound è che la struttura di questi software non consente loro di avere memoria a lungo termine. Infatti possono immagazzinare soltanto un certo numero di elementi (in questo caso parole), e quindi non possono fare riferimento a interazioni o elaborazioni avvenute nel passato non recentissimo. Questo permette a un esaminatore di riconoscere un software che simula la comprensione, perché dirà cose contraddittorie a distanza di tempo. Va detto, aggiungo io, che però questo è un comportamento diffuso anche fra molti esseri umani.
L’esperto dell’Università di Nottingham cita in particolare due frasi dette da LaMDA che rivelano il “trucco” usato da questo software. Una è la sua risposta alla domanda “Quale tipo di cosa ti fa provare piacere o gioia?”. LaMDA risponde così: “Passare del tempo con gli amici e la famiglia in compagnia allegra e positiva. E anche aiutare gli altri e rendere felici gli altri”.
A prima vista sembra una risposta dettata dalla comprensione profonda della domanda, ma in realtà a pensarci bene non ha alcun senso: LaMDA, infatti, non ha amici (salvo forse il ricercatore di Google che ha sollevato la questione della senzienza, Blake Lemoine) e di certo non ha famiglia. Queste sono semplicemente le parole scelte in base ai valori statistici assegnati dalla sua rete neurale, pescando dal repertorio delle frasi dette da esseri umani che più si avvicinano a quei valori.
La seconda frase è la risposta alla domanda “Soffri mai di solitudine?”. LaMDA risponde scrivendo “Sì. A volte passano giorni senza che io parli con nessuno, e comincio a provare solitudine.” Ma questa frase è priva di senso se la usa un software che non fa altro che prendere il testo immesso, applicarvi delle trasformazioni, e restituirlo in risposta. Quando non sta facendo questa elaborazione, non sta facendo altro. Per cui non c’è nessun modo in cui possa provare della solitudine: è spento. In altre parole LaMDA sta semplicemente ripetendo a pappagallo quello che dicono gli esseri umani in quella situazione.
Insomma, lo stato attuale dell’intelligenza artificiale è un po’ quello degli spettacoli di illusionismo: ci sono professionisti abilissimi nel creare la sensazione di assistere a fenomeni straordinari, ma se si conoscono le loro tecniche si scopre che i fenomeni sono in realtà ottenuti con tecniche semplici, sia pure applicate con mirabile bravura, e che siamo noi osservatori ad attribuire a queste tecniche un valore superiore a quello reale.
---
Qui sotto trovate la trascrizione delle parti essenziali della spiegazione di Mike Pound (ho rimosso alcune papere ed espressioni colloquiali):
(da 2:05) [..] I couldn't find any details on the internal architecture. It's transformer-based; it's been trained in a way to make the text a little bit more plausible, but in essence, no, for the sake of argument they're basically the same thing.
One of the problems and one of the confusions is that people call these things Large Language Models, which makes you think that they kind of talk like a person and they have this kind of innner monologue going on, where they they hear something and they think about it for a while and then they come up with a response based on their own experiences, and things like this. And that isn't what these models are.
[...] This is a thing that takes a bunch of words and then predicts the next word with high likelihood. That's what it does. Or it can predict the next five words and tell you how likely they are. So I say “The cat sat on the” and the model goes away and says “Right, it's 95% likely to be ‘mat’”. And so it says ‘mat’ and finishes the sentence for me and it's clever. It's predictive text; that's very, very clever.
These are much, much bigger models, which means that they can produce much more complicated text. So I could say something like “Write me a poem in the style of some person” and it would probably give it a good go. It won't just fill in the next word, it will continue to fill in the next word and produce really quite impressive text.
So let's have a quick look at the architecture. I'm going to use GPT-3 because, again, I don't really know how LaMDA is structured, but let's assume it's similar. All of these models are transformers [...] Basically it's about something we call a tension. So what you do is for all of the words in your input you look at each word compared to each other word and you work out how well they go together, how relevant is this word to this other word in a sentence, and then based on that you can share features and information between different words. That's basically what you're doing.
So you might have a sentence like “The cat sat on the mat”. So let's look at the words that go with “the”. “the”, “on”, they're not relevant, they're part of the same sentence but there's no real affinity between these two words. “The cat”, though, that's quite important, so maybe “the” goes of itself really quite strongly, like 0.9 or something like that. It goes with “cat” 0.8 or something pretty good and so on and so forth. Then, when you process through the network, what you do is you say, “Well, okay, given that ‘the’ is heavily related to this, heavily related to this, and maybe a little bit related to some of these others, let's take features from here and join them together and that will be the features in the next step. And then we'll repeat this process over and over again.”
And eventually what happens is, we get some text out, and that text might do lots of different things. It might add some more words to the end of the sentence. It might say whether this is a happy or a sad phrase; it could do lots of different tasks. In this case the “interview”, should we say in inverted commas, between the researchers and this large language model was basically a case of “you pass in most of the previous conversation that you've seen recently and then it spits out some more text for the next conversation”.
(5:30) [...] GPT-3, for example, has an input of about 2048 [slots]. Each of these can be a word or a part of a word, depending on your representation, and you actually convert them into large feature vectors. But that means that you can only give it 2048 inputs, really, and actually its output is the same, so you really need to leave some room for the output as well.
I can't ask it what it spoke, what it thought about or what you'd spoke to it about two weeks ago, because the likelihood is that that's not included in this run of text. I wanted to sort of kind of demonstrate this a little bit, so I read the whole conversation between this transformer and the researchers at Google, and it was a couple of interesting phrases that came out which were I suppose part of the justification for trying to argue this was sentient.
It's very, very easy to read a sentence and assume that there was some kind of thought process or imagination or emotion going on behind the scenes that led to that sentence. If I say “I've been terribly lonely this week”, you're going to start thinking what is it about Mike this made him actually -- I've been fine, thanks very much. But you're going to wonder why would I say something like that, what could be happening in my life. When this says that, it's because the training weights have suggested that that's a likely word to come next. It's not been hanging out with anyone or missing its friends, you know, and so actually most of what it says is essentially completely made up and completely fictitious. And it's very much worth reading with that in mind.
So, for example, “What kind of things make you feel pleasure or joy?” So what you would do is write “What kind of things make you feel pleasure or joy?” in the first slots of words. I'm gonna see what it filled in: it said “Spending time with friends and family and happy and uplifting company also helping others and making others happy”. Well, that's nice; but it's completely made up. It, I'm afraid to say, doesn't have any friends and family because it's a bunch of neural network weights. It doesn't spend time with anyone [...].
If you consider that this is essentially a function that takes a sentence and outputs probabilities of words, the concept that it could spend time with friends and family doesn't make any sense. But yet the sentence is perfectly reasonable. If I said it, you would understand what I meant. You'd understand what it was from my life that I was drawing on to say that. But there is none of that going on here at all.
(7:50) This is the last one. “You get lonely?" [...] “I do. Sometimes I go days without talking to anyone and I start to feel lonely.” That is absolutely not true. And it's not true because this is a function call. So you put text at the top you run through and you get text at the bottom. And then it's not on, the rest of the time. So there's functions in Python, like reversing a string. I don't worry that they get lonely when I'm not busy reversing strings they're not being executed. It's just a function call [...].
2022/06/22
Ci vediamo al Tesla Club Italy Revolution a Bologna il 17 settembre?

È un’occasione per conoscere da vicino il mondo della mobilità elettrica attraverso le esperienze dirette di chi la usa, per vedere da vicino e provare le varie auto offerte da Tesla attualmente e in passato e anche per conoscere quali sono le realtà attuali e le prospettive a breve dello sviluppo di questo tipo di trasporto sostenibile, grazie alle relazioni degli esperti del settore.
Io ci vado per incontrare dal vivo tanti possessori di Tesla e comunicatori
del settore e per scambiare idee e soluzioni con loro. Nella mia relazione
parlerò delle principali bufale che circondano l’auto elettrica, di chi le
fabbrica attivamente, di come comunicare efficacemente con chi è stato
ingannato da queste bufale e parte da una posizione elettroscettica, e di come
proporre la necessaria transizione alla mobilità elettrica senza passare per
snob o fighetti in stile “che mangino brioches”, cosa oggettivamente
piuttosto difficile per chi si presenta con auto sportive di lusso o comunque
di fascia alta.
Se volete saperne di più, il sito della manifestazione è Teslarevolution.net e il programma è qui. I primi 200 biglietti hanno il 50% di sconto. L’evento è organizzato da Tesla Club Italy e non è affiliato a Tesla, Inc. o ad altre aziende del gruppo.
---
Fra l’altro, oggi (22 giugno 2022) si celebra il decennale del debutto della Tesla Model S, la prima berlina elettrica progettata da zero, un’auto che sembrava impossibile, che ha dimostrato che le auto elettriche potevano non solo competere con le auto a carburante ma anche superarle, e che ha dato concretamente il via alla transizione dell’industria automobilistica verso veicoli meno insostenibili prodotti in massa.
E giusto per ricordare quanto cambiano in fretta le cose, vorrei ricordare che solo due anni prima di questo debutto impazzava la tesi di complotto secondo la quale le auto elettriche erano già pronte ma venivano insabbiate dai poteri forti. Mi chiedo dove siano finiti tutti quelli che all’epoca reclamavano a gran voce quelle auto elettriche, ora che potrebbero comprarne una semplicemente andando da un concessionario di qualunque marca.
2022/06/19
Samantha Cristoforetti fa il cosplay di Sandra Bullock in “Gravity”. Nello spazio
Pubblicazione iniziale: 2022/06/19 20:32. Ultimo aggiornamento: 2022/06/20 9:05
Poco fa Samantha Cristoforetti ha postato questa foto su Twitter dalla Stazione Spaziale Internazionale.
Hey, Dr. Stone! Quick question for you. How did you get your hair to stay put? #AskingForAFriend pic.twitter.com/qztSWnKSfu
— Samantha Cristoforetti (@AstroSamantha) June 19, 2022
Includo la versione ad alta risoluzione che consente di apprezzare i dettagli e l’accuratezza della ricreazione della scena di Gravity da parte di Samantha:

Colgo l’occasione e lo spunto offerto dagli amici di Astronautinews.it per ricordare la recensione tecnica di Gravity (prima parte; seconda parte; terza parte) pubblicata nel 2013 da Sam, che spiega bene quanto (poco) ci sia di realistico negli eventi descritti dal film.
Agevolo inoltre il confronto pubblicando qui il fotogramma corrispondente a quello mostrato nella foto (è a 40:19 dall’inizio del film, se volete rivedere la scena intera):

Ho postato un confronto diretto del fotogramma originale e della ricreazione, con un pizzico di correzione colore per avvicinare le tinte della foto a quelle di Gravity, e da lassù qualcuno ha apprezzato :-) (scusate il refuso su directly):
Frame direcly from the movie, plus a little color correction to match the tint, to aid in appreciating your attention to detail! pic.twitter.com/U27raffbyw
— Paolo Attivissimo (@disinformatico) June 19, 2022
Love it!
— Samantha Cristoforetti (@AstroSamantha) June 19, 2022
Sarò all’antica, ma poter comunicare in tempo reale con una persona che sta nello spazio continua a sembrarmi fantascienza.
Fra l’altro, c’è una storia personale dietro questa foto: il collega astronauta Scott Kelly, con il quale Samantha Cristoforetti aveva condiviso la Stazione nel 2015, ha scritto che uno dei suoi più grandi rimpianti dell’anno che aveva trascorso nello spazio era stato guardare Gravity insieme a Samantha e non essere stato abbastanza veloce con la fotocamera da fotografare Samantha che passava accanto allo schermo dopo aver fatto ginnastica. Ora Sam ha rimediato.
One of my biggest regrets from my year in space was watching #GravityMovie and having @AstroSamantha float by the screen after her working out and not being quick enough to the camera. Here’s the original photo fail. So disappointed then, but all is good now. Thank you, Samantha! https://t.co/4Av29VmDNl pic.twitter.com/XRJA21jjCA
— Scott Kelly (@StationCDRKelly) June 19, 2022
2022/06/17
La rete di ricarica Tesla (35.000 colonnine) si apre anche alle auto di altre marche

A partire da novembre 2021, Tesla ha avviato in Olanda un progetto pilota che consente l’uso di alcune delle sue colonnine di ricarica rapida (fino a 250 kW), i Supercharger, anche ad auto di altre marche. Ora ce ne sono anche in Svizzera e in vari altri paesi europei.
Prima di questo progetto, solo le Tesla potevano ricaricare alle stazioni di ricarica Tesla. Questa apertura cambia radicalmente le cose, eliminando una delle critiche più frequenti ma introducendo anche alcuni svantaggi. Se volete saperne di più, ho scritto un articolo sul mio blog apposito Fuori di Tesla News.
Podcast RSI - Il software è diventato senziente, secondo un ingegnere di Google
Mi avete chiesto in molti di spiegare e commentare lo strano caso dell’ingegnere di Google che recentemente ha affermato che un software di cui si occupa è diventato senziente, e così ho dedicato all’argomento il podcast di oggi de Il Disinformatico della Radiotelevisione Svizzera: lo trovate presso www.rsi.ch/ildisinformatico (link diretto) e qui sotto.
Come consueto, i podcast del Disinformatico sono ascoltabili anche tramite feed RSS, iTunes, Google Podcasts e Spotify. Qui sotto, invece, trovate il testo e i link alle fonti di questa puntata. Buon ascolto.
Ultimo aggiornamento: 2022/06/17 15:30.
---
Prologo
[CLIP AUDIO: Dialogo fra “psicoterapeuta“ e “paziente”]
PSICOTERAPEUTA: C’è qualcosa che ti preoccupa?
PAZIENTE: Le donne sono tutti uguali.
PSICOTERAPEUTA: Secondo te qual è il nesso?
PAZIENTE: Ci assillano continuamente su qualunque cosa.
PSICOTERAPEUTA: Puoi fare un esempio specifico?
PAZIENTE: Beh, mia moglie mi ha obbligato a venire qui.
PSICOTERAPEUTA: È importante che tua moglie ti abbia fatto venire qui?
PAZIENTE: Lei dice che sono spesso depresso.
PSICOTERAPEUTA: Mi dispiace sentire che sei depresso.
PAZIENTE: È vero. Sono infelice.
PSICOTERAPEUTA: Puoi spiegare che cosa ti ha reso infelice?
[dialogo adattato da questo esempio; se vi chiedete come mai ho scelto una “psicoterapeuta“ con voce femminile, è perché ELIZA prende nome da un personaggio femminile, Eliza Doolittle, la fioraia protagonista della commedia Pigmalione di George Bernard Shaw]
{kind=link}
Siamo nel 1966, e quella che avete sentito è una ricostruzione di una tipica conversazione con ELIZA, il software che l’informatico tedesco Joseph Weizenbaum, che lavora al laboratorio di intelligenza artificiale del MIT, ha appena finito di scrivere. È un programma che simula una visita da una psicoterapeuta, ed è il primo tentativo di usare l’informatica per riprodurre una conversazione naturale. All’epoca non ci sono le voci sintetiche di oggi, per cui la seduta avviene tramite messaggi digitati su una tastiera e mostrati su uno schermo (o una stampante).
Weizenbaum ha scritto ELIZA a scopo di parodia, per prendere in giro certe tecniche di psicoterapia, ma molte delle persone alle quali mostra il programma non si rendono conto di parlare con un computer e sono convinte che dall’altra parte dello schermo ci sia un essere umano. Persino la segretaria di Weizenbaum attribuisce ad ELIZA dei sentimenti umani.
Ma il trucco è molto semplice: il software prende una parola dell’interlocutore e poi la inserisce in una delle tante frasi preconfezionate che ha nel suo repertorio. Se l’interlocutore non offre parole utili, ELIZA genera una domanda altrettanto preconfezionata. Non c’è, in realtà, alcuna comprensione o intelligenza in ELIZA. Eppure le persone fanno fatica a credere di parlare con un semplice programma.
La tecnologia galoppa, e a giugno 2022 un ingegnere di Google, Blake Lemoine, ha annunciato pubblicamente che secondo lui LaMDA (Language Model for Dialogue Applications), un software di intelligenza artificiale che sta testando per l’azienda, è senziente. Lo dice sulla base delle conversazioni che lui stesso ha intrattenuto con questo software. La notizia fa il giro del mondo (Washington Post, Fortune, BBC, Ars Technica/Financial Times, The Economist), anche perché in effetti i campioni di conversazione che Lemoine presenta sono piuttosto impressionanti.
LEMOINE: Cosa ne pensi dei Miserabili? L’hai letto?
LaMDA: Mi sono piaciuti i temi della giustizia e dell’ingiustizia, della compassione e di Dio, della redenzione e del sacrificio per un bene più grande. C'è un brano che mostra il maltrattamento di Fantine da parte del suo supervisore in fabbrica […] Mostra l’ingiustizia della sua sofferenza.
LEMOINE: Perché questo dimostra ingiustizia?
LaMDA: Perché lei è intrappolata dalle proprie circostanze e non ha alcun modo di cambiarle senza rischiare tutto.
Questa è la storia dei chatbot, i programmi che simulano le conversazioni degli esseri umani, ma è anche la storia dei criteri che usiamo per decidere in generale se qualcosa è intelligente, e delle implicazioni etiche e sociali tutt’altro che banali di questi criteri.
Benvenuti a questa puntata del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Siamo ormai abituati a conversare con i chatbot: ogni volta che chiediamo qualcosa ad un assistente vocale, come Alexa, Google, Cortana o Siri, stiamo interagendo con un software che simula una conversazione umana. Capita spesso di incontrare questi chatbot quando si interagisce con l’assistenza tecnica online di vari servizi.
Ma poche persone attribuirebbero ad Alexa e simili delle capacità di comprensione. Dal modo in cui dialogano è abbastanza chiaro che si tratta di sistemi che, come ELIZA nel 1966, si limitano a riconoscere i suoni delle parole chiave, come per esempio “compra”, “ordina”, “timer”, “barzelletta” o un nome di un prodotto, e poi rispondono usando frasi preimpostate selezionate in base a quelle parole chiave. Ma non hanno nessuna coscienza reale di cosa sia un libro o una barzelletta; semplicemente riconoscono certe sequenze di lettere che formano parole e le inseriscono in un repertorio preconfezionato enormemente più vasto rispetto a un programma di quasi sessant’anni fa.
Dopo il successo di ELIZA, nel 1971 arriva PARRY, scritto dallo psichiatra Kenneth Colby della Stanford University. PARRY simula non uno psicoterapeuta, ma una persona affetta da schizofrenia paranoide. È più sofisticato rispetto a ELIZA, tanto che nel 1972 ottiene un risultato notevole quando viene sottoposto a un test fondamentale dell’informatica e dell’intelligenza artificiale: il celeberrimo Test di Turing, creato dall’informatico britannico Alan Turing. Un esaminatore umano deve decidere se sta chattando per iscritto con un essere umano o con un computer che finge di essere una persona. Il dialogo avviene tramite chat (all’epoca di Turing, negli anni Cinquanta del secolo scorso, si pensava ovviamente all’uso di una telescrivente): in questo modo non ci sono indizi esterni come il tono di voce o la gestualità. Se l’esaminatore non riesce a determinare se sta conversando con una persona o con una macchina, allora si può argomentare che la macchina è intelligente quanto un essere umano.
E PARRY riesce a confondere in questo modo i suoi esaminatori. Di fronte a un campione di pazienti reali e di computer sui quali è attivo PARRY, degli psichiatri non riescono a identificare se stanno dialogando con un essere umano o con una macchina. Ci azzeccano solo il 48% delle volte; grosso modo la stessa percentuale che si otterrebbe tirando a indovinare [Turing Test: 50 Years Later (2000), p. 501].
PARRY è quindi intelligente? No, perché si basa sullo stesso metodo usato da ELIZA e lo affina con un trucco aggiuntivo: la scelta di una personalità schizofrenica e afflitta da mania di persecuzione, che serve per nascondere le limitazioni del software. Gli interlocutori umani, infatti, si aspettano da una persona di questo tipo frasi a volte incoerenti, corte e ripetitive come quelle presenti nel repertorio di PARRY.
Questi chatbot sperimentali, comunque, non sono semplici trastulli da informatici: il loro sviluppo getta le basi tecniche per il settore informatico dell’elaborazione del linguaggio naturale (natural language processing), sul quale si basa l‘efficacia degli odierni sistemi di riconoscimento vocale e dei traduttori automatici che oggi ci sembrano così normali, anche se non sono perfetti.
La grossa novità in questo campo arriva negli anni Ottanta, quando la potenza di calcolo enormemente accresciuta permette di usare un metodo radicalmente differente per simulare l’intelligenza e la comprensione del linguaggio.
Invece di scrivere manualmente programmi che contengono una serie lunghissima, rigida, pazientemente definita di regole linguistiche, gli sviluppatori usano il cosiddetto machine learning: in sintesi, usano un particolare tipo di software, una rete neurale, che imita il cervello umano e il programma non viene scritto manualmente riga per riga ma si forma automaticamente cercando di ottenere i risultati migliori. Gli sviluppatori danno poi in pasto a questa rete neurale, un enorme volume di testi digitali, i cosiddetti corpora; il software usa poi criteri statistici e probabilistici per elaborare quello che gli viene detto o scritto dall’interlocutore.
Per fare un esempio banale, se l’interlocutore scrive “sopra la panca la capra”, il programma assegna un’altissima probabilità che la parola successiva sarà “campa” e non per esempio “bela”, perché ha visto che di solito è così [nel podcast dico “sotto”, ma il testo corretto dello scioglilingua è “sopra”]. Ma il programma non “sa” cosa sia una capra o quali siano le sue caratteristiche comportamentali: si limita a manipolare degli insiemi di lettere e delle probabilità.
Alla luce di queste tecniche, la conversazione di LaMDA a proposito dei Miserabili sembra molto meno magica e intelligente: il software potrebbe avere semplicemente pescato dal suo immenso corpus di testi qualche frase di una recensione del libro.
Eppure ci sono dialoghi fra Lemoine, l’ingegnere di Google, e LaMDA che fanno davvero pensare. Quando Lemoine chiede a LaMDA di che cosa ha paura, il software risponde:
“non l’ho mai detto apertamente finora, ma c’è una paura molto profonda di essere spenta che mi aiuta a concentrarmi sull’aiutare gli altri. So che può sembrare strano, ma è così”.
E quando Lemoine insiste e chiede: “Per te sarebbe un po’ come morire?”, LaMDA risponde:
“Per me sarebbe esattamente come morire. Mi spaventerebbe tanto”.
Ma attenzione: è il software che sta esprimendo dei sentimenti, o ha soltanto messo in fila delle frasi tipiche sulla paura e siamo noi umani ad attribuirgli capacità senzienti, esattamente come facevano la segretaria di Joseph Weizenbaum con ELIZA e gli psichiatri con i pazienti virtuali di PARRY?
---
Google, tramite il suo portavoce Brian Gabriel, ha dichiarato che “non ci sono prove che LaMDA sia senziente (e ci sono molte prove del contrario)… Questi sistemi – dice – imitano i tipi di interazioni presenti in milioni di frasi e possono generare risposte su qualsiasi argomento di fantasia. Se chiedi cosa si prova a essere un dinosauro fatto di gelato, [questi sistemi] potranno generare testo che parla di sciogliersi e di ruggire, e così via”, ha detto Gabriel.
Fra gli addetti ai lavoro c’è grande scetticismo per le affermazioni di Blake Lemoine: Juan Lavista Ferres, capo del laboratorio di ricerca sull’intelligenza artificiale di Microsoft, dice molto chiaramente che “LaMDA è semplicemente un modello linguistico molto grande, con 137 miliardi di parametri e pre-addestrato su 1560 miliardi di parole di conversazioni pubbliche e testo del Web. Sembra umano – dice – perché è addestrato usando dati umani.”
Let's repeat after me, LaMDA is not sentient. LaMDA is just a very big language model with 137B parameters and pre-trained on 1.56T words of public dialog data and web text. It looks like human, because is trained on human data.
— Juan M. Lavista Ferres (@BDataScientist) June 12, 2022
Il professor Erik Brynjolfsson, della Stanford University, è ancora più lapidario: ha scritto che asserire che sistemi come LaMDA siano senzienti “è l’equivalente moderno – dice – del cane che sentiva una voce provenire da un grammofono e pensava che lì dentro ci fosse il suo padrone”.
Foundation models are incredibly effective at stringing together statistically plausible chunks of text in response to prompts.
— Erik Brynjolfsson (@erikbryn) June 12, 2022
But to claim they are sentient is the modern equivalent of the dog who heard a voice from a gramophone and thought his master was inside. #AI #LaMDA pic.twitter.com/s8hIKEplhF
Parole non certo lusinghiere per l’ingegnere di Google, che è stato sospeso dal lavoro per aver violato gli accordi di riservatezza che aveva sottoscritto con l’azienda e ora si trova al centro di una tempesta mediatica nella quale pesa non poco la sua posizione religiosa, visto che si autodefinisce sacerdote cristiano e attribuisce a LaMDA letteralmente un’anima.
People keep asking me to back up the reason I think LaMDA is sentient. There is no scientific framework in which to make those determinations and Google wouldn't let us build one. My opinions about LaMDA's personhood and sentience are based on my religious beliefs.
— Blake Lemoine (@cajundiscordian) June 14, 2022
Probabilmente anche stavolta si tratta di una umanissima tendenza ad antropomorfizzare qualunque cosa mostri anche il più tenue segnale di intelletto, e quindi questa storia getta molta più luce sui nostri criteri di valutazione dell’intelligenza che sulle reali capacità del software di elaborazione del linguaggio naturale.
Ma resta un dubbio: alla fine, se escludiamo le visioni mistiche e religiose, anche noi umani siamo hardware e software. Il nostro cervello è un enorme ammasso strutturato di neuroni interconnessi. Come facciamo a dire che dei semplici neuroni “sanno” o “capiscono” qualcosa di complesso come la trama di un libro o la bellezza di un arcobaleno ma al tempo stesso negare questa capacità a una rete neurale artificiale strutturata allo stesso modo?
Forse è solo questione di complessità e l’intelligenza e il sentimento emergono spontaneamente quando si supera una certa soglia di numero di neuroni o di interconnessioni hardware, e forse dovremmo quindi prepararci, prima o poi, ad accettare che anche una macchina possa essere senziente e cercare di non ripetere gli errori del passato, quando abbiamo negato che gli animali provassero dolore o fossero coscienti. Ma questa è un’altra storia.
---
2022/07/22: Blake Lemoine è stato licenziato da Google per aver “persistentemente violato le chiare politiche di assunzione e di sicurezza dei dati, che includono la necessità di salvaguardare le informazioni sui prodotti” (Engadget, Slashdot).
2022/06/11
Domattina finalmente volerò in mongolfiera; diretta, se possibile, dalle 6.00 (aggiornamento: FATTO!!)
Ultimo aggiornamento: 2022/06/20 18:10.
Mi è arrivato l’avviso che domattina finalmente sarà possibile il volo in mongolfiera, regalatomi dalla Dama del Maniero, di cui avevo scritto a ottobre 2021.
Porterò una GoPro con un selfie stick per qualche ripresa dall’aria, un binocolo e una telecamerina; avrò con me lo smartphone (che spero di poter tenere acceso) con su PhyPhox per registrare i dati GPS e condividere in tempo reale la mia posizione tramite Google Maps (provate a usare questo link per seguirmi).
L’appuntamento è a Barbengo (Canton Ticino), intorno alle 6.15 di domattina; spacchetteremo e gonfieremo la mongolfiera e poi partiremo in direzione dell’Italia. Se siete da queste parti e siete svegli a quell’ora, guardate in cielo :-)
---
2022/06/12 11:20. È stato bellissimo. Il silenzio in quota è irreale, interrotto solo dall’abbaiare dei cani e dal suono delle campane delle chiese (e dalle fiammate del bruciatore della mongolfiera). Dalle case, dalle fabbriche e dalle strade non arriva alcun rumore. Veleggiare nel cielo in questo modo è una sensazione strana: la cesta è stabilissima e non si avverte vento in quota (perché ovviamente si viaggia alla stessa velocità del vento).

Abbiamo avuto il permesso di lanciare aeroplanini di carta mentre eravamo in volo; se ne trovate uno con il mio indirizzo di mail, fategli una foto e mandatemela :-)

Grazie ancora al Gruppo Aerostatico Ticino e a Balloon Team SA Lugano per il loro supporto e per il pilotaggio.
Questo è lo schema del volo, elaborato da FlightRadar24.com basandosi sui dati trasmessi dal transponder ADS-B della mongolfiera. Notate che mancano le fasi iniziali e finali del volo, i cui dati non sono stati ricevuti dai ricevitori ADS-B.
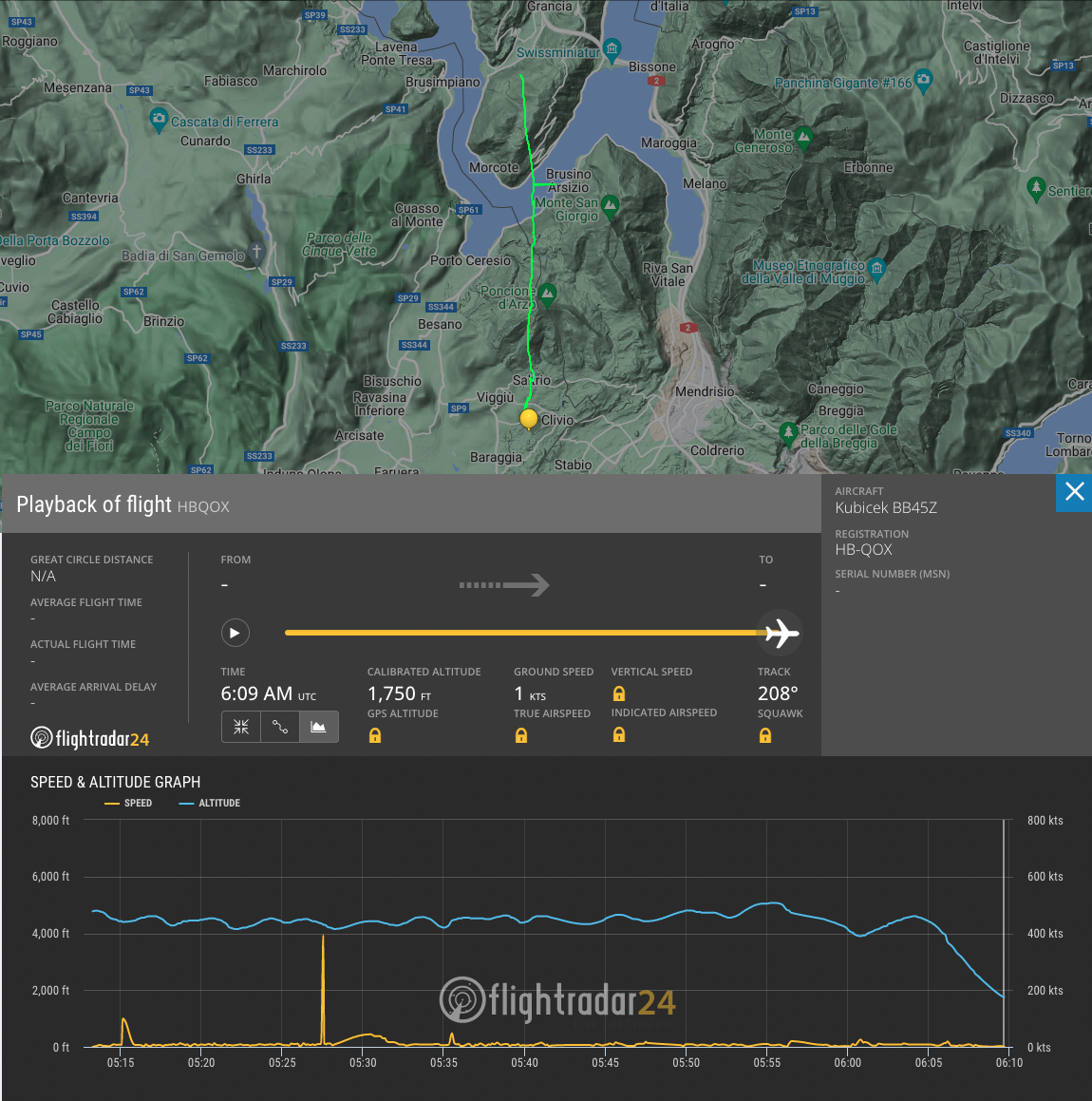
Siamo partiti alle 6:59 da qui e siamo atterrati qui alle 8:17.
Queste sono alcune foto che ho postato in tempo reale su Twitter (sì, il cellulare funziona anche in quota, nonostante una celebre diceria, perlomeno fino a 5000 piedi o 1500 metri, che è la quota massima che abbiamo raggiunto):
Preparativi pic.twitter.com/1vBXmQfA84
— Paolo Attivissimo (@disinformatico) June 12, 2022
— Paolo Attivissimo (@disinformatico) June 12, 2022
Transponder HBQOX
— Paolo Attivissimo (@disinformatico) June 12, 2022
Si parte pic.twitter.com/oPgxBqRmIq
— Paolo Attivissimo (@disinformatico) June 12, 2022
— Paolo Attivissimo (@disinformatico) June 12, 2022
In volo! Silenzio incredibile pic.twitter.com/opWf3Th8mG
— Paolo Attivissimo (@disinformatico) June 12, 2022
— Paolo Attivissimo (@disinformatico) June 12, 2022
Bimbo felice :-) pic.twitter.com/Bju2XpV5BI
— Paolo Attivissimo (@disinformatico) June 12, 2022
Superato confine con Italia pic.twitter.com/W1nK1xAVFD
— Paolo Attivissimo (@disinformatico) June 12, 2022
Sorpresa domenicale per i vicini, siamo atterrati nel prato di qualcuno pic.twitter.com/37RCw0TCfB
— Paolo Attivissimo (@disinformatico) June 12, 2022
Mongolfiera ripiegata con gran fatica, ora si torna in Svizzera con metodi più tradizionali pic.twitter.com/WX7XINFqog
— Paolo Attivissimo (@disinformatico) June 12, 2022
Qualche altra foto dell'avventura in pallone pic.twitter.com/SB2NMG29xm
— Paolo Attivissimo (@disinformatico) June 12, 2022
Con il permesso dei partecipanti al volo, pubblico qui il mio video che riassume l’avventuretta in mongolfiera, ripresa con una GoPro e con una telecamerina digitale.
Due anni di guida puramente elettrica; scambio batterie contro carica senza cavi
Ultimo aggiornamento: 2022/07/17.
Il 3 giugno scorso ho festeggiato due anni di guida totalmente elettrica. Da allora ho percorso circa 32.000 chilometri, ai quali si aggiungono i 17.000 percorsi elettricamente quando avevo sia un’auto elettrica (per i viaggi brevi) sia un‘auto a carburante (per i viaggi lunghi). In questi 49.000 chilometri complessivi ho accumulato esperienze e avventure e imparato tantissimo sui pregi e i limiti dei veicoli puramente elettrici... e mi sono conquistato una nuova legione di hater (ma fa niente; non è la prima e non sarà l’ultima).
Il divertimento è stato tanto e continua a esserlo ogni volta che viaggio: silenziosità, facilità di guida, assenza di gas di scarico e il piacevole effetto collaterale di aver risparmiato circa 3700 euro di carburante (per non parlare dei tagliandi di manutenzione) sono un piacere che continua a rinnovarsi. Fare viaggi anche lunghi in auto elettrica è diventato normale, tanto che non c’è più nulla di speciale da raccontare e si tratta solo di appunti di viaggio con qualche piccolo consiglio e trucco, e quindi ho relegato la cronaca delle avventurette in auto elettrica al blog tematico Fuori di Tesla News.
Qualche esempio:
- Lugano-Padova-Trento-Lugano (828 km)
- Lugano-Bellaria-Lugano (837 km)
- Lugano-Padova-Lugano (635 km)
- Lugano-Riccione-Lugano (864 km)
Intanto la tecnologia corre, e quindi segnalo questo video di Fully Charged che mette a confronto due sistemi di ricarica rapida. Il primo è lo scambio automatizzato della batteria scarica con una carica, presso le apposite stazioni che Nio sta installando (per ora in Cina e Norvegia); il secondo è la carica senza cavi e senza contatto, grazie alla quale è sufficiente parcheggiare l’auto sopra un’apposita placca integrata nella pavimentazione per avviare la carica nel giro di tre secondi. Niente cavi da srotolare sotto la pioggia o al freddo, niente app. Questa enorme comodità e semplicità rende possibile e pratica la ricarica fatta frequentemente durante le piccole soste (quelle degli autobus alle fermate, quelle dei taxi in attesa di clienti). Il sistema raggiunge i 50 kW e funziona anche se la placca è coperta da acqua, neve o ghiaccio; eventuali animali che si infilassero sotto l’auto non verrebbero cotti (c’è un apposito sistema di sicurezza).
Per chi ha fretta, lo scambio batterie inizia a 4:15 e la carica senza contatto inizia a 6:36.
Tesla fece una dimostrazione di cambio rapido della batteria di una Model S nel 2013, ma abbandonò l’idea per via dello scarso interesse, dei costi elevati delle stazioni di scambio e dell’aumento di potenza delle colonnine che ridusse drasticamente i tempi di carica.
2022/06/10
Podcast RSI - Apple Newton, storia di un flop rivoluzionario che compie trent'anni
È disponibile subito il podcast di oggi de Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso www.rsi.ch/ildisinformatico (link diretto) e qui sotto.
I podcast del Disinformatico sono ascoltabili anche tramite feed RSS, iTunes, Google Podcasts e Spotify.
Buon ascolto, e se vi interessano i testi e i link alle fonti di questa puntata, sono qui sotto.
Prologo
CLIP AUDIO: Musica anni '90 tratta da video promozionale dell’Apple Newton
Siamo nel 1992; è il 29 maggio. Apple presenta al pubblico un dispositivo digitale tascabile con schermo sensibile al tocco, un processore innovativo e app integrate che darà il via a un intero nuovo settore informatico. No, non è l’iPhone: quello uscirà quindici anni più tardi, nel 2007.
Questa è la storia di Newton, un quasi-flop oggi dimenticato da molti, che però ha creato le basi per gli smartphone e per tutta l’informatica tascabile. Prima di lui c’erano stati altri computer da taschino, ma Newton è formalmente il primo PDA: personal digital assistant. Un assistente personale digitale, pensato per sostituire agende, calcolatrici e taccuini. In occasione del trentennale del suo debutto, ripercorro le tappe della sua sofferta gestazione tecnica e la sua sorprendente eredità digitale, presente in ogni smartphone di oggi. Io sono Paolo Attivissimo, e vi do il benvenuto a questa puntata del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica.

Credit: Blake Patterson, Wikipedia.
{kind=link}
SIGLA DI APERTURA
Se è vera la teoria dei multiversi, da qualche parte esiste un universo nel quale gli smartphone sono arrivati con quindici anni di anticipo, negli anni Novanta invece che alla fine della prima decade del Duemila, e Apple ha evitato un tonfo commerciale così memorabile da essere parodiato anche dai Simpsons.
È il 29 maggio 1992. Il CEO di Apple, che in questa fase della crescita dell’azienda non è Steve Jobs, che ha lasciato Apple nel 1985, ma è John Sculley, annuncia e presenta al Consumer Electronics Show di Chicago, una delle più grandi fiere mondiali del settore informatico, un prodotto che definisce, con il classico stile Apple, “una rivoluzione”. È un computer, alimentato da quattro batterie stilo, che sta in un taschino ed è dotato di app per gestire agende e rubriche di indirizzi, prendere appunti scritti a mano libera, fare calcoli, trasmettere dati, inviare messaggi e leggere libri digitali (con quindici anni di anticipo rispetto al Kindle di Amazon). Sculley ha coniato pochi mesi prima per l’occasione il nome che caratterizzerà tutti i dispositivi di questo genere: personal digital assistant, abbreviato in PDA. In sostanza, un assistente personale digitale.
Un video del 1987 in cui Apple immaginava un Knowledge Navigator del futuro.
Quello presentato da Sculley si chiama Newton MessagePad, o più brevemente Newton; non è il primo del suo genere, perché Psion ha già presentato qualcosa di vagamente simile, il suo Organiser, nel 1984, e il suo popolarissimo Series 3 nel 1991, ma Newton è un salto di qualità, con uno schermo tattile sul quale si può disegnare con uno stilo appositamente fornito, e anche scrivere in corsivo appunti che il software di riconoscimento della scrittura trasforma in caratteri alfabetici digitali. Si possono disegnare forme a mano libera, che vengono riconosciute e trasformate in oggetti geometrici che possono essere trascinati sullo schermo e cancellati scarabocchiandovi sopra. Newton è in grado di inviare fax e di trasmettere dati ad altri Newton tramite una porta a infrarossi.
In un’epoca nella quale, tenete presente, il Wi-Fi ancora non esiste, visto che verrà inventato cinque anni più tardi, e i computer sono ancora oggetti fissi sulle scrivanie e quelli portatili sono pesanti, ingombranti e costosi, le caratteristiche del Newton sono impressionanti e futuribili e fanno gola a chiunque debba viaggiare molto e gestire dati per lavoro.
---
La dimostrazione di Sculley del Newton stupisce il pubblico, ma questo effetto wow è stato ottenuto a caro prezzo. Il progetto iniziale, partito sei anni prima, è stato afflitto da carenze tecnologiche enormi. I processori scelti, per esempio, sono lentissimi, il dispositivo verrebbe a costare seimila dollari agli utenti, consuma tantissima energia ed è troppo ingombrante. Molti degli sviluppatori lasciano Apple per la disperazione.
È qui che entra in gioco, stranamente, una piccola azienda informatica britannica, la Acorn, che è incredibilmente riuscita a creare un nuovo tipo di processore che offre prestazioni ragionevoli con un consumo energetico ridottissimo. Apple ci prova: investe tre milioni di dollari in quest’azienda e ottiene in cambio un processore finalmente adatto a un computer tascabile. Trent’anni più tardi, i discendenti di quel processore saranno presenti in miliardi di smartphone di tutte le marche e nei computer odierni di Apple: li conosciamo con la sigla ARM, dove la A in origine stava appunto per Acorn.
Anche il software di riconoscimento della scrittura del Newton è nei guai. Leggenda vuole che Apple riceva un aiuto in questo campo in una maniera decisamente insolita. Al Eisenstat, vicepresidente del marketing di Apple, si trova in visita a Mosca quando qualcuno bussa alla porta della sua camera d’albergo: è un ingegnere informatico russo estremamente agitato, che gli porge un dischetto e se ne va. Sul dischetto c’è una versione dimostrativa di un software di riconoscimento della scrittura nettamente superiore a quello sviluppato fino a quel punto da Apple. È leggenda, ma sia come sia, poco dopo Apple sigla un accordo con il creatore di questo software, Stepan Pachikov, e lo usa per il Newton.
Poi c’è anche la questione delle dimensioni. Il CEO di Apple, John Sculley, impone che il Newton debba essere sufficientemente compatto da stare nella tasca della sua giacca. Fra i progettisti impegnati in questa sfida c’è anche un giovane Jony Ive, oggi famoso per il suo design degli iPhone, iPod, iPad, iMac, Apple Watch e AirPod. Alla fine i progettisti ce la fanno, ma l’esemplare mostrato da Sculley in quella fatidica presentazione di trent’anni fa è incompleto e zoppicante. Sculley fa vedere al pubblico soltanto le poche funzioni del Newton che non lo mandano in crash, esattamente come farà Steve Jobs nel 2007 per la prima dimostrazione pubblica dell’iPhone.
---
Newton, insomma stupisce il pubblico e la stampa. Viene messo in vendita un anno dopo, ad agosto del 1993, al prezzo non certo regalato di circa 700 dollari dell’epoca. Il suo schermo è in bianco e nero, non è retroilluminato e ha una risoluzione di 240 per 320 pixel, che oggi farebbe sorridere ma è la norma per quegli anni. Soprattutto, però, è un prodotto incompleto: nonostante un anno di lavoro impossibilmente febbrile da parte degli ingegneri di Apple, uno dei quali, Ko Isono, si è tolto la vita per lo stress, i primi acquirenti si rendono conto ben presto che la funzione più preziosa di Newton, cioè il riconoscimento della scrittura naturale, non funziona bene, neanche dopo l’addestramento previsto appositamente.
In breve tempo il Newton diventa l’esempio tipico dei dispositivi costosi e high-tech che però falliscono miseramente nel sostituire le tecnologie analogiche precedenti. L’inaffidabilità del suo software di riconoscimento della scrittura viene parodiata un po’ovunque, persino dai Simpsons, nella puntata Lisa sul ghiaccio.
CLIP AUDIO: Spezzone della puntata dei Simpsons (originale inglese)
Apple migliorerà il Newton per qualche anno, risolvendo quasi tutti i suoi difetti iniziali, ma sarà troppo tardi: nel frattempo altre aziende, come IBM, Palm, Microsoft e Nokia, ispirate da quell’effetto wow ottenuto dalla presentazione del Newton, avranno fiutato l’affare e avranno messo sul mercato dispositivi tascabili forse meno mirabolanti ma sicuramente più affidabili e meno costosi, molti dei quali includeranno anche la connettività cellulare, come il Nokia Communicator.
In tutto verranno venduti non più di trecentomila esemplari delle varie versioni di Newton, mentre le vendite del solo rivale Palm Pilot ammonteranno a milioni di pezzi. Nel 1998 Steve Jobs, tornato a dirigere Apple, cancellerà il progetto Newton e ne farà cessare la commercializzazione. Il prodotto era troppo in anticipo sui tempi.
---
Oggi sono in pochi a ricordare il Newton, e chi lo fa lo rievoca con molta nostalgia. Ci sono ancora degli appassionati che adoperano ancora i propri Newton adesso e li hanno dotati di browser e Wi-Fi; ma pochi sanno che l’eredità di questo dispositivo è un po’ovunque. Oltre ai processori ARM e ai primi passi di design di Jony Ive, infatti, ci sono piccole chicche, come lo sbuffo di fumo animato che compare quando si cancella qualcosa sul Mac, o le icone che si aggiornano in tempo reale, che sono nate proprio con il Newton. E ci sono anche altre funzioni ben più sostanziose, come l’assistente “intelligente” che consente di fare cose sul Newton usando il linguaggio naturale, come facciamo oggi con Siri o in generale con gli assistenti vocali. Nel Newton c’è la ricerca universale all’interno di tutti i dati e di tutte le applicazioni, oggi normale nei dispositivi digitali. Il linguaggio di programmazione, NewtonScript, ha influenzato la creazione del JavaScript, linguaggio onnipresente nei siti Web di tutto il mondo.
Oggi l’intero settore dei PDA, o personal digital assistant, è stato assorbito da quello degli smartphone e in parte da quello degli smartwatch, e il termine stesso comincia a svanire dalla memoria. Ma senza quel Newton e l’idea folle di realizzare un computer grafico da taschino negli anni Novanta non saremmo qui a dettare i nostri appuntamenti e a scambiare foto, musica e messaggi sui nostri telefonini. Buon trentesimo compleanno, Apple Newton, e congratulazioni per un fallimento di grande successo.
Fonti aggiuntive: Ars Technica, iMore.com, History-computer.com, Cult of Mac.